
How the Fortune 500 Scores on AI Agent Readiness
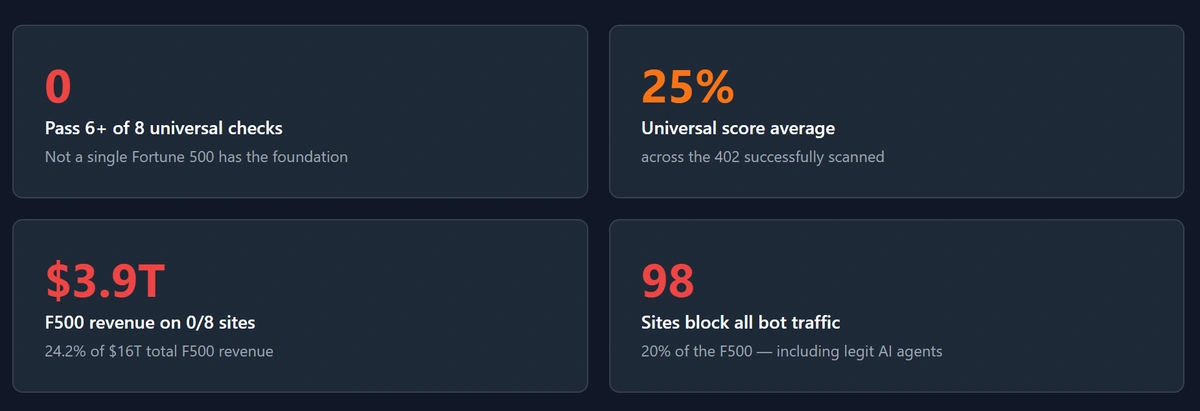
This month we ran a 16-check AI agent readiness audit against every domain in the Fortune 500. The headline finding: zero of 500 sites pass more than 5 of the 8 universal-tier discovery checks that AI agents now use to decide whether a site is worth engaging with. The Fortune 500 average on universal-tier discovery is 25%. The two highest-scoring sites in the entire dataset, Dell Technologies (#31) and Opendoor Technologies (#425), tied at 5 of 8.
The agentic web is the new entrance funnel. Buyers in 2026 ask ChatGPT, Perplexity, Claude, or Google AI Overviews before they open a competitor tab or walk into a showroom. Two standards bodies started codifying what “agent ready” means in 2026, and we ran their combined criteria against the largest companies in America to see how the country’s most-resourced businesses are positioned for that funnel. The answer is bluntly that they are not, and the size of the company turns out not to be the predictor anyone would expect.
This is original research. The methodology, scanner code, and per-site results are reproducible. The sample is the entire population of the Fortune 500, not a survey. The full sortable leaderboard with every company, every check, and the underlying scoring is published here.
Methodology
Two recent standards bodies converged on the same problem from different angles. Cloudflare published isitagentready.com in 2026, a free public scanner that grades a site on 13 emerging agent-readiness signals, all observable over plain HTTP without executing JavaScript. Google’s Chrome team published guidance for AI agent-friendly websites around the same time, with 8 recommendations for making web pages usable by browser-using AI agents like ChatGPT computer use, Claude computer use, Gemini, and Copilot Vision.
The two sets of criteria address different layers of the same problem. Cloudflare’s checks ask whether an agent can find your site at all, by reading robots.txt, sitemaps, AI bot rules, content signals, llms.txt, and a handful of well-known endpoints. Google’s checks ask whether an agent can use your site once it has arrived, by reading semantic HTML, ARIA roles, label-input linkage, and visual interaction signals.
We combined both into a 4-tier model and ran 16 HTTP-only checks against every primary domain in the Fortune 500. Source list: gigasheetco/fortune-500-domains, deduplicated to 500 unique primary domains. Twenty-five concurrent workers, total scan time under ten minutes. No headless browser, no authenticated probes. Sites that returned 403 even when we presented a Chrome User-Agent were flagged as “blocks all bots,” which is functionally equivalent to being invisible to an agent acting on a customer’s behalf.
The four tiers in the model:
- Tier 1, Universal Discovery (8 checks): robots.txt, sitemap, link headers, markdown content negotiation, AI bot rules, content signals, llms.txt, agent skills index.
- Tier 2, API and Auth (3 checks): API catalog (RFC 9727), OAuth/OIDC discovery, OAuth protected resource (RFC 9728). Treated as not applicable for marketing-only sites.
- Tier 3, Advanced Discovery (2 checks): web bot auth, MCP server card.
- Tier 4, Agent UX (3 checks): semantic HTML, label-input linkage, ARIA on actionable elements.
The full check list is HTTP-observable and free to re-run. The complete report, including a sortable leaderboard of all 500 companies, every per-site check result, and the underlying scoring methodology, which lives here.
Finding 1: zero of the Fortune 500 pass more than 5 of 8 universal checks
Universal-tier discovery is the layer that determines whether an AI agent can locate, classify, and read a site. It’s also the cheapest tier to fix. Most of the eight checks are configuration changes rather than engineering programs, and they’re standard scope inside generative engine optimization services.
Across all 500 sites, the best universal score in the entire Fortune 500 is 5 of 8. Two sites tied at the top: Dell Technologies (#31) and Opendoor Technologies (#425). Dell’s setup is worth studying as a positive example: their published robots.txt explicitly handles AI bot user-agents, and they ship a real llms.txt at the root of the domain. Both files are HTTP-readable, lightweight, and exactly the kind of work the rest of the Fortune 500 has not done. The Fortune 500 average is 25%, or 2 of 8 checks passed per site. 137 sites (27.4% of the list) score zero. 98 of those (19.6% of the Fortune 500) actively block all bot traffic, returning 403 even to a Chrome User-Agent.
Bot blockers in the Top 50 alone include Cardinal Health, Chevron, Marathon Petroleum, Kroger, Ford, UPS, Lowe’s, Humana, Intel, and GE. For an AI agent acting on behalf of a real customer trying to research, compare, or transact with these companies, the experience is roughly the same as if the website did not exist.
Finding 2: revenue weighting makes the picture worse
The Fortune 500 represents roughly $16 trillion in annual revenue. When we weight the readiness scores by revenue rather than by site count, the picture sharpens.
- $3.9 trillion (24% of total Fortune 500 revenue) sits on sites that pass zero universal-tier checks.
- $2.93 trillion (18%) sits on sites actively blocking bots entirely.
- Only $0.33 trillion (2%) sits on sites that pass 4 or more of 8 universal checks.
- 97.9% of Fortune 500 revenue runs on websites that fail more than half of the basic AI agent readiness checks.
The largest revenue concentrations in the U.S. economy are the least-prepared for the entrance funnel buyers actually use in 2026.
Finding 3: company size is not a predictor
This is the finding we did not expect. We assumed the Top 100 would skew higher than the rest of the list, on the theory that bigger companies have larger digital teams and bigger budgets. The data does not support that assumption.
The Top 100 average is 20%. The 101 to 250 cohort averages 20%. The 251 to 500 cohort averages 20%. Within rounding, the three bands are identical. The Top 100 is actually slightly more likely to block all bots than the bottom half of the list (21% versus 18%).
The leaders we found are scattered across industries and revenue tiers. Behind Dell and Opendoor at 4 of 8 are Nvidia, DXC Technology, Builders FirstSource, Waste Management, Gap, Expeditors, Halliburton, Peter Kiewit, Sempra, Booking Holdings, Owens & Minor, Constellation Brands, and Campbell Soup. There is no industry or revenue-band pattern. The pattern is strategic intent. Companies that have actively prioritized agent readiness rank ahead of companies fifty times their size that have not.
The Fortune 50 laggards are particularly striking. Berkshire Hathaway (#7) scores 0 of 8. Johnson & Johnson (#37) scores 0 of 8. Procter & Gamble (#47) scores 0 of 8. Twelve more Top 50 names block bots entirely. The biggest companies in America have the worst infrastructure for the next entrance funnel.
Finding 4: zero of 500 publish three modern standards
Three of the eight universal checks have not been deployed by a single Fortune 500 company.
- Agent Skills Index: 0 of 500.
- API Catalog (RFC 9727): 0 of 500.
- OAuth Protected Resource (RFC 9728): 0 of 500.
Even the companies whose business model depends on integrations, including Salesforce, Stripe, Visa, Microsoft, and Oracle, have not deployed the standard well-known endpoints that would let agents discover their APIs and auth surfaces automatically. This is a category that is currently zero-percent owned by the Fortune 500. The first sites to deploy these standards will hold an unusually long lead, in part because the standards are well-defined RFCs that are unlikely to be reinvented in the next two to three years.
Finding 5: Tier 4 (Agent UX) is the bright spot, and it is misleading
The Tier 4 results look almost good when read alongside the other three tiers.
- Universal Discovery average: 25%.
- API and Auth average: 0.4%.
- Advanced Discovery average: 8.7%.
- Agent UX average: 73%.
Most Fortune 500 sites use semantic HTML, link labels to inputs properly, and avoid clickable-div anti-patterns. An AI agent that has already arrived on the page can usually click and fill what it needs to.
The reason Tier 4 scores so much higher is not that the Fortune 500 has invested in agent UX. It’s that Google’s recommendations overlap heavily with WCAG accessibility standards. Fifteen years of compliance-driven accessibility work translates more or less directly to agent UX. The DOM that’s friendly to a screen reader is friendly to a Claude or ChatGPT browser-use agent. The agent UX score the Fortune 500 earned in this study is largely an accidental dividend of accessibility programs that started a decade and a half ago for entirely different reasons.
The implication matters more than the score. Sites are mostly fine at interacting with agents that visit. They are failing at letting agents find them in the first place. Long-running investments in traditional SEO and accessibility have produced an agent-friendly interaction layer almost as a side effect, but neither of those programs ever pointed an engineering team at the discovery surface that an AI agent actually reads first.
What this means for the agentic web
Two conclusions follow from the data, and both have commercial implications.
The first is that discovery is the binding constraint in 2026, not interaction. The work that has been done historically (mostly accessibility, with some traditional SEO) helps agents that have already arrived. The work that has not been done (robots.txt audits, llms.txt, AI bot rules, content signals, agent skills, API catalogs) is what determines whether agents arrive at all. Investing in agent UX without first fixing discovery is paving the driveway of a house with no street.
The second is that the most-resourced companies in America are not protected by their resources in this category. The Fortune 50 averages no better than the back half of the list. The leaders are scattered across industries and ranked anywhere from #31 to #425. Strategic intent, not budget or headcount, is the predictor. That makes the field unusually open. A challenger that prioritizes agent readiness this quarter can be more discoverable to AI agents than the largest companies in its category, regardless of relative size.
Most universal-tier checks are configuration changes a single engineer can complete in a sprint. The companies that ship them in the next twelve months will own the agent-search category in their vertical for the twenty-four months that follow.
What companies should do this quarter
The four highest-leverage moves for any site, Fortune 500 or otherwise:
- Ship
llms.txt. A single static file, roughly 50 lines, zero dependencies. Tells AI agents which pages on your site you consider canonical and citation-worthy. - Add explicit AI bot User-agent rules in
robots.txt. AllowGPTBot,ChatGPT-User,OAI-SearchBot,Google-Extended,PerplexityBot,Claude-User,Claude-SearchBot,ClaudeBot, andanthropic-aiby default, and remove any blanket disallow rules that sweep them up by accident. - Add Content-Signal directives in
robots.txtto declare your AI training and AI search preferences explicitly, so agents can respect or honor your stance without having to guess. - Publish an Agent Skills Index. Zero of 500 Fortune 500 sites have one, which means the first companies in any category to deploy one own a piece of the agent-search experience that nobody else can claim yet.
What companies should do this year
The longer-horizon list assumes you have an engineering team and want to compete seriously for agent-driven discovery rather than ride defaults.
Deploy markdown content negotiation. Cloudflare ships this as a single toggle on its CDN. Audit aggressive bot management policies and verify that legitimate AI agents can reach your site, not just human users with normal browsers. Publish API Catalog at /.well-known/api-catalog if you have public APIs. Publish OAuth/OIDC discovery and OAuth Protected Resource metadata if you have authenticated endpoints. Consider an MCP Server Card if you want agents to transact, not just read.
Each of these is a configuration or metadata change rather than a software rewrite. None requires the kind of coordinated multi-team program that compliance overhauls used to need.
How traditional SEO and accessibility do and do not help
A reasonable question after looking at this data is whether the SEO and accessibility work most enterprise web teams have been doing for years should already cover most of the agent-readiness surface. The honest answer is that those programs cover the second half of the funnel and not the first.
Accessibility programs (driven by WCAG and ADA exposure) have produced the semantic HTML, ARIA labeling, and label-input linkage that show up as 73% Tier 4 scores in this study. That work was done for screen reader users and keyboard navigation, but it transfers cleanly to AI browser-use agents because the DOM signals are the same. This is real and durable value.
Traditional SEO programs (focused on Google’s classic crawler) have produced sitemaps, internal linking, schema markup on product and article pages, and clean URL structures. Some of that overlaps with agent discovery, but most of it does not. The classic SEO crawler arrives at a site already knowing the site exists. AI agents in 2026 increasingly arrive without knowing the site exists, looking for explicit signals (llms.txt, AI bot rules, content signals, agent skills) that traditional SEO has never had to produce.
The result is the lopsided pattern this study surfaced: high Tier 4 scores from accidental accessibility transfer, low Tier 1 scores because traditional SEO was never aimed at this part of the problem. Companies that want to close the gap need a discovery audit specifically. Auditing as if SEO and accessibility cover it will miss the layer that actually determines whether agents find the site.
Want to know how your site scores on AI agent readiness? Grade any domain with AgentGrade in seconds, then talk to us about the exact configuration changes to ship next.
Grade Your Site's AI VisibilityFrequently Asked Questions
What does “AI agent readiness” actually mean?
AI agent readiness is the set of HTTP-observable signals a website provides to autonomous AI agents (ChatGPT, Claude, Perplexity, browser-use systems, MCP clients) that determine whether the agent can find, read, classify, and interact with the site. It splits into two layers: discovery (can the agent find you and understand what you offer) and interaction (can the agent operate the page once it gets there). This study measures both.
Why is the Fortune 500 average only 25% on universal-tier discovery?
The eight universal-tier checks are recent. Several of them (llms.txt, content signals, agent skills) only emerged as standards in 2025 and 2026. Most enterprise web teams have not received a mandate to deploy them yet, and the standards bodies pushing them (Cloudflare, Google, IETF) have only recently begun publishing canonical guidance. The 25% average reflects how new the category is more than how careless the companies are.
Are the Fortune 500 sites that score zero hopelessly behind?
No. Most universal-tier checks are configuration changes a single engineer can complete in a sprint. A site at 0 of 8 today can reach 4 or 5 of 8 in two to three weeks of focused work. The harder problem is recognizing that the work has not been done yet, not the work itself.
Will allowing AI bots hurt SEO or expose proprietary content?
Allowing AI bots is independent of traditional Google ranking signals. Google’s classic crawler and AI agents are different user-agents with different rules. Allowing one does not affect the other. On proprietary content, AI bot rules can be set at directory or path granularity, so a company can allow AI agents to read public marketing pages while disallowing access to authenticated or sensitive sections.
How does AI agent readiness relate to AI search citation?
Readiness is the floor; citation is the ceiling. A site has to pass discovery checks before AI assistants will read and cite it confidently. After that, citation depends on content quality, schema, brand authority, and the kinds of factors that determine traditional SEO performance. This study measures the floor. Companies that want to be cited need to clear it first and then invest in the citation layer.
Why doesn’t company size predict readiness?
Because agent readiness is so new that established processes and budgets have not caught up to it yet. The companies that score well are the ones where someone (often a single engineer or product manager) recognized the trend early and shipped the relevant configuration. That kind of early-mover work happens roughly as often at a #425 company as at a #7 company. It is not a function of resources.
Can I run this scan on my own site?
Yes. The scanner is HTTP-only, open-source, and free to re-run on any list of domains. For an instant read on a single site, AgentGrade grades how well ChatGPT, Claude, and Perplexity can find, read, and cite any URL in seconds. To let your own agent run these checks directly, our MCP server for SEO exposes the same audits as tools it can call. The methodology section above lists the source list and tooling, and the full Fortune 500 leaderboard is browsable so you can see how peers in your category scored. We also offer per-domain agent readiness audits as part of our paid engagements, which extend the scan with prioritized remediation, the exact configuration to deploy, and a comparison against your category competitors.
Limitations
Three limitations are worth naming.
First, the scanner is HTTP-only by design. It does not execute JavaScript, attempt authenticated probes, or inspect APIs that are gated behind login flows. A site might pass agent UX checks via JavaScript-rendered DOM that this scanner cannot read. Conversely, a site might block bots at an upstream WAF in ways that don’t show up as a clean 403. Both effects are small at the scale of 500 sites but worth flagging.
Second, the standards themselves are evolving. Agent Skills Index, MCP Server Card, and Web Bot Auth are early enough in their lifecycles that scoring against them today partly measures who has heard about them rather than who has deployed them well. The 0 of 500 results on those checks should be read with that lens.
Third, agent readiness is not a complete proxy for agent visibility. A site can pass every universal check and still rank poorly in ChatGPT or Perplexity citations because of separate factors (content quality, schema, brand authority). The scanner measures the floor, not the ceiling. Passing matters; passing alone is not sufficient.
The bottom line
Zero of the Fortune 500 are ready for the agentic web by the standards two major standards bodies have started publishing. The average score is 25% on the most basic discovery checks. Three modern standards have zero deployments across the entire dataset. The largest companies in America are no better positioned than mid-cap competitors, and in some cases meaningfully worse.
The discovery layer is broken across nearly the entire Fortune 500, while the interaction layer is in surprisingly good shape because of fifteen years of accessibility work that translates almost directly to agent UX. The headline problem in 2026 is robots.txt, llms.txt, AI bot rules, content signals, and the well-known endpoints that determine whether an agent can find a site at all. It is not React DOM patterns.
Most of the fixes are configuration changes a single engineer can complete in a sprint. The companies that ship them in the next twelve months will own a category for the twenty-four months that follow. The data says the field is unusually open. The hard part is recognizing that the work has not been done yet.






